Relation Model
Relational Data Structure
We define a relation to be a subset of a Cartesian product of a list of domains.
Formally, given sets , a relation is a subset of Thus a relation is a set of n-tuples where .
And the difference here are :
- Assign attribute name to every domain
- Finite set
Relation Schema
are attributes, each attribute of a relation has a name, and is a relation schema. is a relation on the relation schema .
Relation Instance
The current values(a.k.a. relation instance) of a relation are specified by a table. An element of is a tuple, represented by a row in a table.
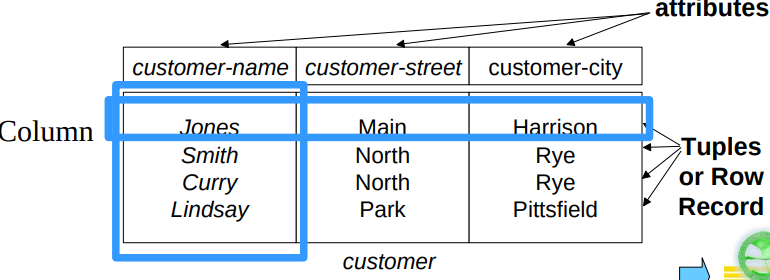
- Order of tuples is irrelevant, tuples may be stored in an arbitrary order
- Order of attributes is irrelevant
- For all relations, the domains of all attributes be atomic
- Attributes names must be different
- Several attributes can have the same domain
- Tuples are not duplicate
Super Key
is a relation schema, is a super key for ,for any , no two distinct tuples have the same values on . That is, if and are in and , then . Values for are sufficient to identify a unique tuple of each possible relation by "possible ".
A candidate key of en entity set is a minimal super key. Although several candidate keys may exist, one of the candidate keys is selected to be the primary key.
Candidate Key has two properties:
- Uniqueness. No legal value of ever contains two distinct tuples with the same value for
- Irreducibility. No proper subset of has the uniqueness property.
Foreign Key
For , , includes the Primary Key of , is called a foreign key referencing . is called the referencing relation of the foreign key dependency. is called the referenced relation of the foreign key.
Integrity Constraint
Integrity constraint of primary key: each specified column of primary key is assumed to be not null.
Referential integrity constraint: the value of foreign key in any tuple of relation are either null or must appear as the value of primary key of a tuple of relation .
Fundamental Relational-Algebra-Operations
We have six basic operators:
- Select
- Project
- Union
- Set difference
- Cartesian Product
- Rename
Select
Notation , is called the selection predicate, defined as where is a formula in propositional calculus consisting of terms connected by and, or , not.
Project
Notation: where , are attribute names and is a relation name.
The result is defined as the relation of columns obtained by erasing the columns that are not listed. And the duplicate rows will be removed since relations are sets.
Union
Notation: For to be valid:
-
and must have the same number of attribute
-
The attribute domains must be compatible
-
And the attribute name can be not the same
Set Difference
Notation: For to be valid, the and has the same requirements with union operation.
Cartesian Product
Notation: Combine information from and . Assume that there are relations in , relations in , there will be in ; Assume that has attributes and has attributes, there will be in
Rename
Allow us to rename and therefore to refer to the result of relational-algebra expressions. And allow use to refer to a relation by more than one name.
returns the expression under the name of .
Additional Relational-Algebra-Operations
We define additional operations that do not add any power to the relation algebra but simplify common queries.
Set Intersection
Notation: Having the same requirements with union operation.
And we have:
Join
And the is
Natural Join
Natural join is the default of join: is the same attribute of and .
Outer Join
An extension of the join operation to avoid loss of information. Computes the join and then adds tuples from one relation that does not match tuples in other relation to the result of the join; use null value to fulfill the nonexistent attribute.
And there are three outer join:
- Left outer join
- Right outer join
- Full outer join
Extended Relational-Algebra-Operations
Null Values
It is possible for tuples to have a null value denoted by null for some of their attributes.
Null signifies an unknown value or that a value does not exist. The result of any arithmetic expression involving null is null. Aggregate functions simply ignore null values. Duplicate elimination and grouping, null is treated like any other value and two null are assumed to be the same.
Comparisons with null values return the special truth value: unknown. And we can extend logic to three values with:
-
Unknown or true is true
Unknown or false is unknown
Unknown or Unknown is unknown
-
True and unknown is unknown
False and unknown is false
Unknown and Unknown is unknown
-
Not unknown is unknown
Modification Of the Database
Deleting
where is a relation and is a relation algebra query.
Insertion
where is a relation and is a relation algebra query.
Updating
Each is either the ith attribute of , if this attribute is not updated or if the attribute is to be updated, as an expression.