Index
Basic Concepts
Indexing mechanism used to speed up access to desired data.
Search key is an attribute or set of attributes used to look up records in a file. And an index file consisting of records (called index entries) of the form:

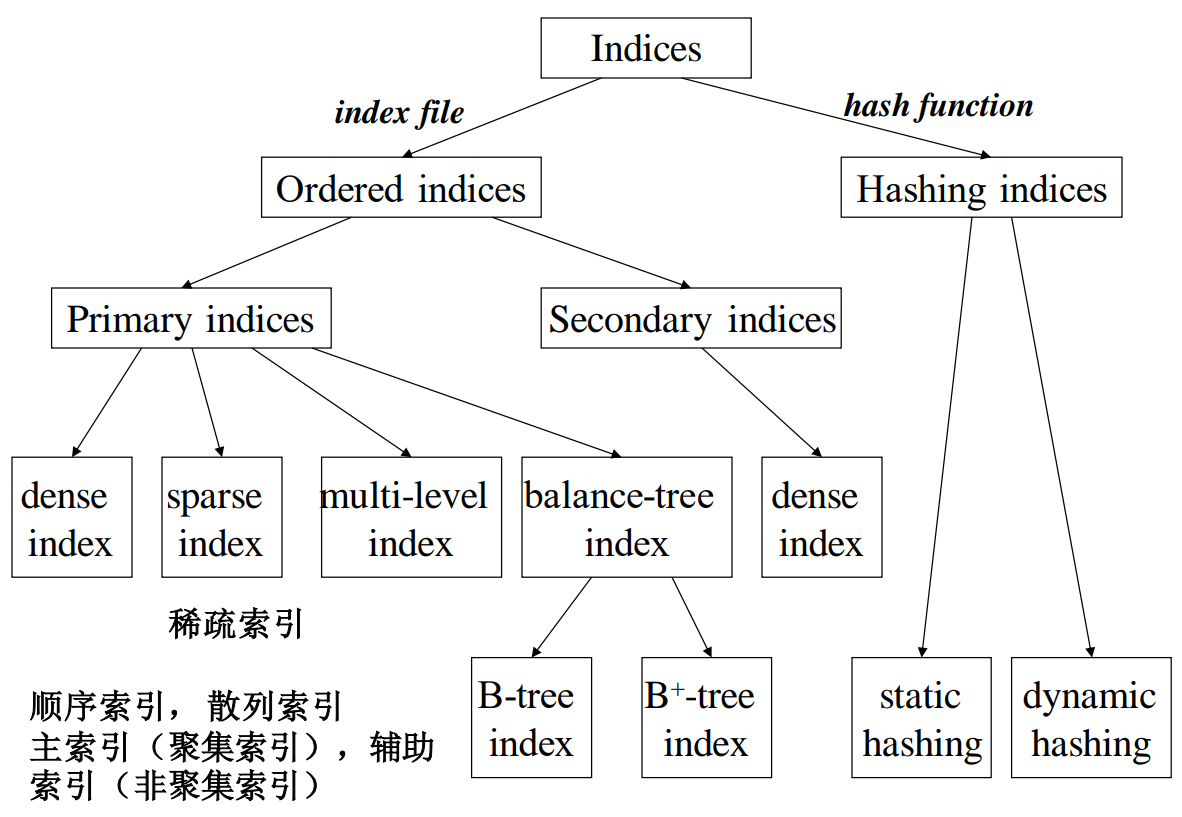
Two basic kinds of index:
- Ordered index: search keys are stored in sorted order
- Hash index: search keys are distributed uniformly across buckets using a hash function
Index Evaluation Metrics:
- Access types supported efficiently
Records with a specified value in the attribute
Records with an attribute value falling in a specified range of values
Access time
Insertion time
Deletion time
Space overhead
Ordered Index
In an ordered index, index entries are stored sorted on the search key value.
Primary index: in a sequentially ordered file, the index whose search key specifies the sequential order of the file, also called as clustering index. The search key of a primary index is usually but not necessarily the primary key and ordered sequential file with a primary index is called index-sequential file.
Secondary index: an index whose search key specifies an order different from the sequential order of the file, also called non-clustering index.
Dense Index: index record appears for every search key in the file.
Sparse Index: contains index records for only some search key values. And to locate a record with search-key value we need to:
- Find index record with largest search key value <
- Search file sequentially starting at the record to which the index record points
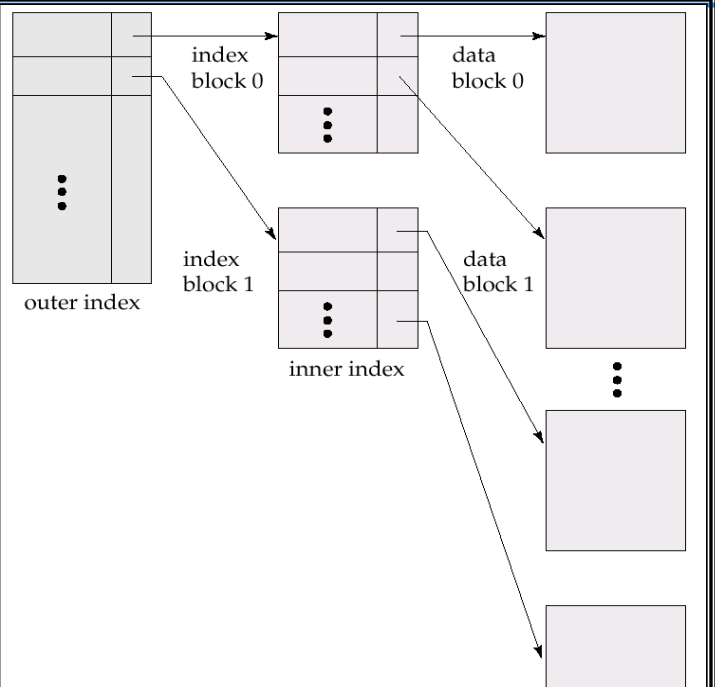
Multilevel Index
If primary index does not fit in memory, access becomes expensive. So to reduce number of disk accesses to index records, treat primary index kept on disk as s sequential file and construct a sparse index on it.
- Outer index: a sparse index of primary index
- Inner index: the primary index file
If the outer index is still too large to fit in main memory, yet another level of index can be created and so on. But index at all levels must be updated on insertion pr deletion from the file.
Index Update
Deletion
If deleted record was the only record in the file with its particular search-key value, the search-key is deleted from the index also.
For single-level index deletion:
- Dense index: delete the pointer when storing pointers to all records or update the pointer when storing pointer to the first record.
- Sparse index: nothing done or replace with next search-key value or updates the pointer
The multi-level deletion are simple extensions of the single-level deletion.
Insertion
For single-level index insertion:
- Perform a look up using the search-key value appearing in the record to be inserted.
- Dense index: insert index/add pointer/update pointer
- Sparse index: no change/insert index/update pointer
The multi-level insertion are simple extensions of the single-level insertion.
Secondary Index
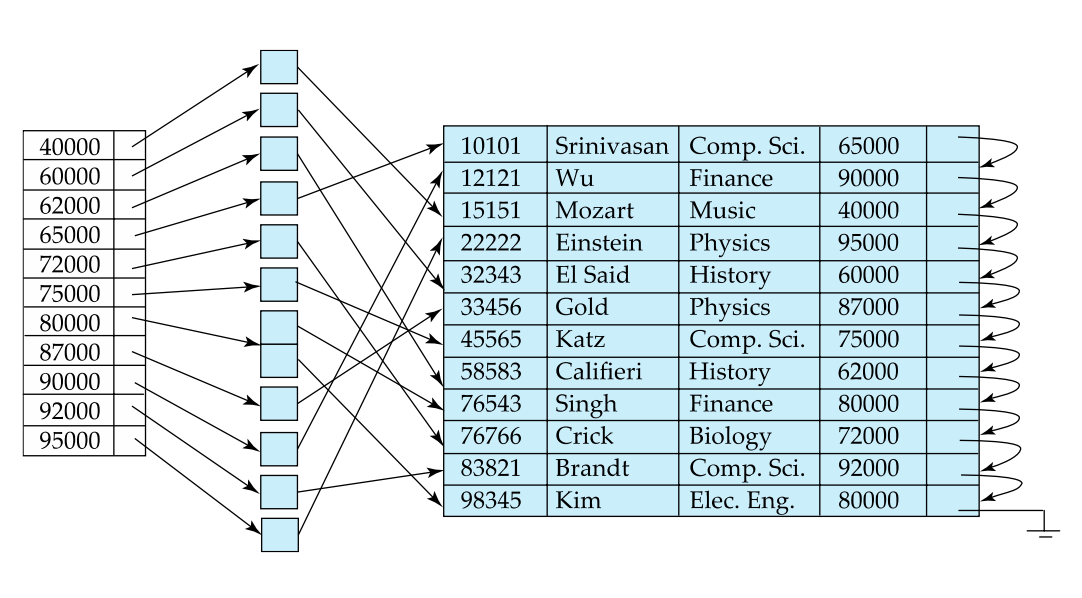
There are some differences between primary and secondary index:
- Secondary index have to be dense
- Index offers substantial benefits when searching for record
- When a file is updated, every index on the file must be updated. Updating index imposes overhead on database modification
- Sequential scan using primary index is efficient, bu a sequential scan using a secondary index is expensive, as each scan may fetch a new block from the disk.
B+ Tree
No thing to say.
Hash Index
A bucket is a unit for storage containing one or more records, typically a disk block. A hash function is a function from the set of all search key to the set of all bucket addresses. Hash function is used to locate records for access, insertion and deletion. In a hash file organization we obtain the bucket of a record directly from its search-key value using a hash function.
Hash Function
Typical hash function perform computation on the binary representation of the search key. An ideal hash function is
- Uniform: each bucket is assigned with the same number of search-key values from the set all possible values
- Random: Each bucket will have the same number of records assigned to it irrespective of the actual distribution of search-key values in the file
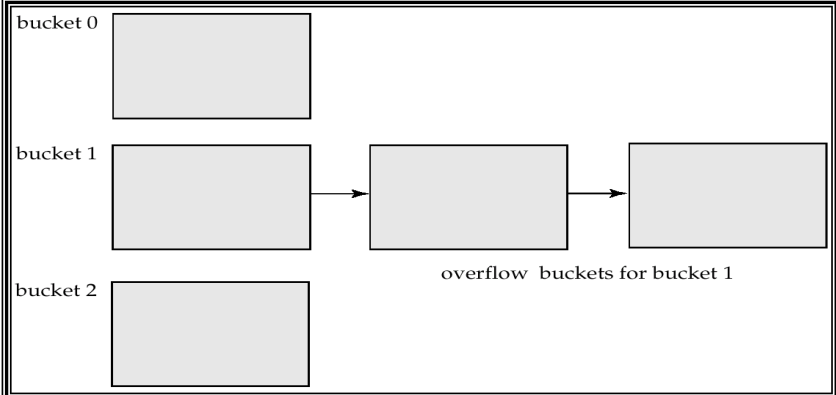
Bucket Overflow Handling
Bucket overflow can occur because of:
- Insufficient bucket
- Skew in distribution of record: multiple records have the same search-key value or chosen hash function produces non-uniform distribution of key values.
Handling the overflow using the overflow chain: the overflow buckets of a given bucket are chained together using a linked list.
A hash index organize the search keys with their associated record pointers into a hash file structure. And strictly speaking, every hash index is a secondary index.
Deficiencies of Static Hashing
In static hashing, hash function maps search-key values into a fixed set of bucket addresses.
- When databases grow with time, if initial number of bucket is small, performance will degrade due to too much overflows
- If file size at some point in the future is anticipated and number of buckets allocated accordingly, significant number of space will be wasted initially
- When database shrinks, again space will be wasted.
One solution is to periodic reorganization of the file with a new hash function, but it is very expensive.
Index Definition in SQL
create index b-index on branch(branch-name);
drop index <index-name>
And when creating index on multiple attributes, the index only can be used efficiently when fetching only records that satisfy all conditions.